Deconstructing the Database
On YouTubeRich Hickey at JaxConf 2012Problem
Common to Rich Hickey, he starts with a proposition that the biggest problem in programming is complexity. According to Ben Moseley and Peter Marks's "Out of the Tar Pit", the major contributors to complexity are state and [flow of] control, and the solutions functional programming and Edgar F. Codd's relational model of data. Rich accepts the relational model (declarative programming) being superior to imperative means of data processing (e.g. object-oriented or procedural programming), but carries on critiquing its model and common client-server implementations.
Lack of Basis
Due to relational databases not modelling nor storing time explicitly, computations resulting from their contents aren't repeatable. Under a dataset that's in constant change, a response to a query today may differ from the response of tomorrow. This leads to coupling questions with reporting, where the question of what to display is combined with the query to fetch the data --- the justified fear of querying at separate times leading to inconsistent views of the data.
Consistency and Scale
Rich briefly alludes to limitations with monolithic architectures and asks, how many value propositions of relational databases can we retain while gaining from distributed systems? People are trading in consistency for performance, gaining unnecessary complexity, and that's not a good trade-off.
Flexibility
Some pieces of data are supposedly hard to represent in a relational model, like irregular and hierarchical data, and multi-valued attributes. Inflexibility in the database will reflect in the app as unnecessary complexity due to having to work-around those limitations.
I think it's valuable here to distinguish between the relational model as it stood originally, in it's ideal normalized form, and today's implementations which are more flexible in types and forms than Rich talks about. Hierarchical and irregular data (presumably data without a schema), however, remain to the most extent clunky, although query recursion and indexing has progressed to where practically they may not present problems. Handling of time --- the basis he's talking about --- remains non-existent beyond the scope of a single database transaction.
Perception and Reactions
With perception being querying and reaction being notifications or change-events, he brings up the problem of basis again --- the reaction to change happens at a later time when the dataset may have already changed again.
I liked his jab at key-value stores: It's the indexing that provides leverage in databases. Without that, they don't differ from other primitive stores like plain files or file systems and shouldn't be called databases.
Approach
He proposes a new distributed and fact-driven database named Datomic.
Information Model
Replace structure (rows and columns) with a collection of single facts. Similarly to RDF, with subject, predicate and object, with the addition of a temporal component. Temporal component isn't limited to time, but can also include the transaction details, author and other auditing information.
This reminds me of the problem of defining the semantics of created_at columns in today's databases. While they're often meant to refer to the time the row was created, I've argued they should be semantically utilized and store the meaningful creation time. That may not coincide with the row creation time. For example, a note created offline should have as its creation time the real time it was created, not the time it was received by the server. Later in the talk, Rich brings up the lack of coordination requirement when querying as a benefit, drawing parallels to the real world's distributive nature. Here, however, he seems to glance over it. How does Datomic's convenient temporal modelling play with the real world we're modelling that accrues facts in a distribute nature? Can you nest them, with the outer one referring to the database's [eventual] knowledge and the inner one to the world? I know we're treading into "eventual consistency" here, but it definitely reduces the value proposition if we're then back to manually propagating time in JOINs.
State
To solve the problem of novelty, he proposes never to change the past, only accrue new facts through assertionss and deletions through retractions of facts. Every other action will reduce down to those two. Similarly to append-only transaction logs, only with their temporal aspect in the foreground, permitting referencing any state between now and beginning.
Implementation
Proposes splitting process (mutation) from perception/reaction (reading), permitting independent scaling. Storage locality would be irrelevant, as the difference between in-memory and on-disk is vastly larger than the difference between local-memory and remote-memory. Leads to treating storage as a key-value black box to store immutable facts, requiring only consistent-reads from it. In addition to fact storage, requires a bit of mutable storage for the root of the tree. The tree itself can be a structurally shared immutable tree:
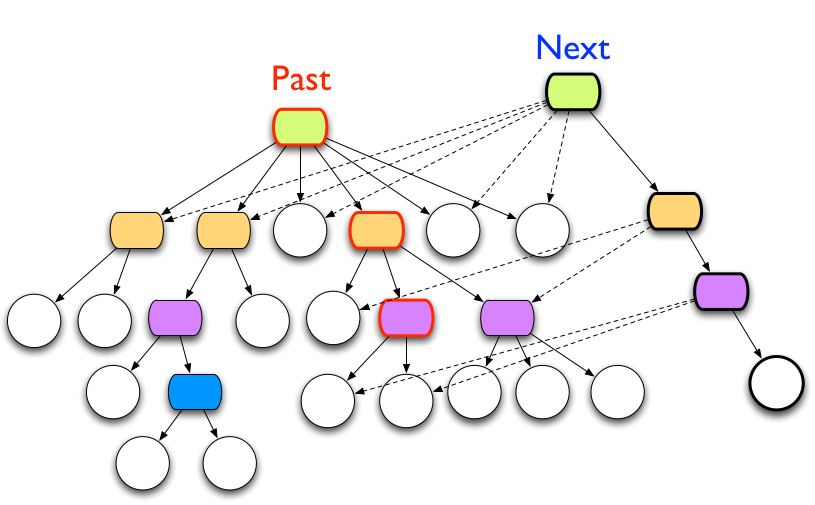
Transaction and Indexing
Indexing seems to be a mix between stored indices and in-memory indices, occasionally dumping the latter out and merging.
Perception
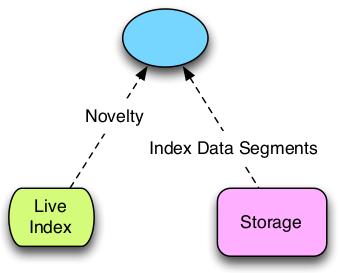
Perception only requires access to the live index and storage. No other components necessary, incl. no coordination necessary or transaction processing system.
Components
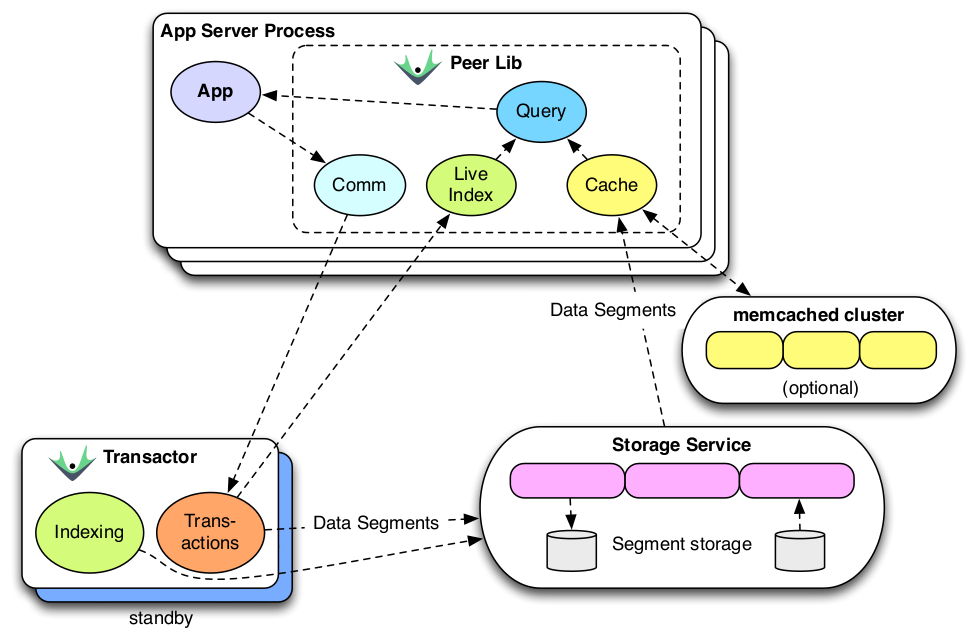
Writing: For storing new facts, an app will communicate with the transactor, which will both store the fact and transmit novelty to peers for a live index. The transactor accepts either new assertions, retractions or transaction functions which will be given the current database and can return either more transaction functions or facts.
Reading: Querying will bypass the transactor and go to storage directly, with optional caching. The query engine can live anywhere, as long as it has access to the storage. The index will be a combination of the durable index from storage and the live index with changes since the last time the storage index was updated.